In the last four parts we went over the problem, high-level design, the design of some internal components, and how we dealt with time. That was enough to start running experiments; we had a full stable system. But sometimes you look at something after you’ve just finished it and think “how did I not do it that way?”. In this part, we’ll talk about that. Shortly after I finished the platform, I thought of a couple of improvements to it but time wasn’t on my side.
The Improved Architecture
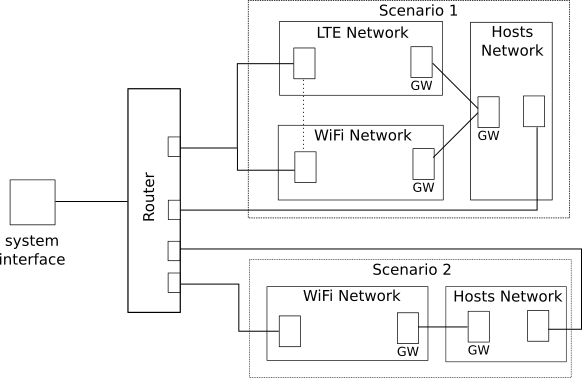
The architecture is very similar to the previous one but with two major changes:
- Each scenario is now a group of simulations, where each simulation hosts a single network.
- There is only a single router for all scenarios.
In this design, the events of a network do not delay the events of another one, allowing each one to scale and progress without being bounded by the others. It also makes each one run on a different thread, since ns3 allows only P2P-connected nodes to be distributed using their MPI module. Here the node aggregation point is in the router itself, and not part of the scenario (as opposed to the previous one where the router gets a reference to the aggregator). The inter-network connection and node-router connection mechanism is left abstract, and could be any kind of Inter Process Communication (IPC). In a single scenario, a node could logically be connected to multiple networks, in this case, they both should have the same Node ID, even if the default ID needed to be manually overridden to ensure consistency.
Conclusion
We did it. We reached the end of this series. Although there’s still a lot to be said about what we did, and even more about what we could have done better, I feel like this gives enough information about the whole design.